Products
-
Full Stack AILearn More
LLM training, AI+science, metaverse, image and speech recognition, natural language processing.
-
Rack and Tower ServersLearn More
Cloud computing,
Virtualization, Big data, Video transcoding.
-
Edge ServersLearn More
Intelligent O&M, quality inspection, fault diagnosis, autonomous driving.
-
Multi-Node ServersLearn More
The ultimate performance experience and new generation of high-density energy-saving data centers.
-
StorageLearn More
Complete product portfolio and full-scenario solutions, build a stable, reliable, intelligent and efficient data infrastructure
-
Cloud InfrastructureLearn More
Virtualization, HCI, Full-Stack RDMA, Millions of IOPS, Elastic Scaling
-
Management SuiteLearn More
Server management suite, infrastructure management platform, online repository of server firmware
-
Datacenter InfrastructureLearn More
High-density, green liquid cooling scenarios, AI computing centers and hyper scale data centers.
Support
-
Support Center
-
Service Center
-
Online Tools
About Us
-
About Us
-
News & Events
-
Other Resources




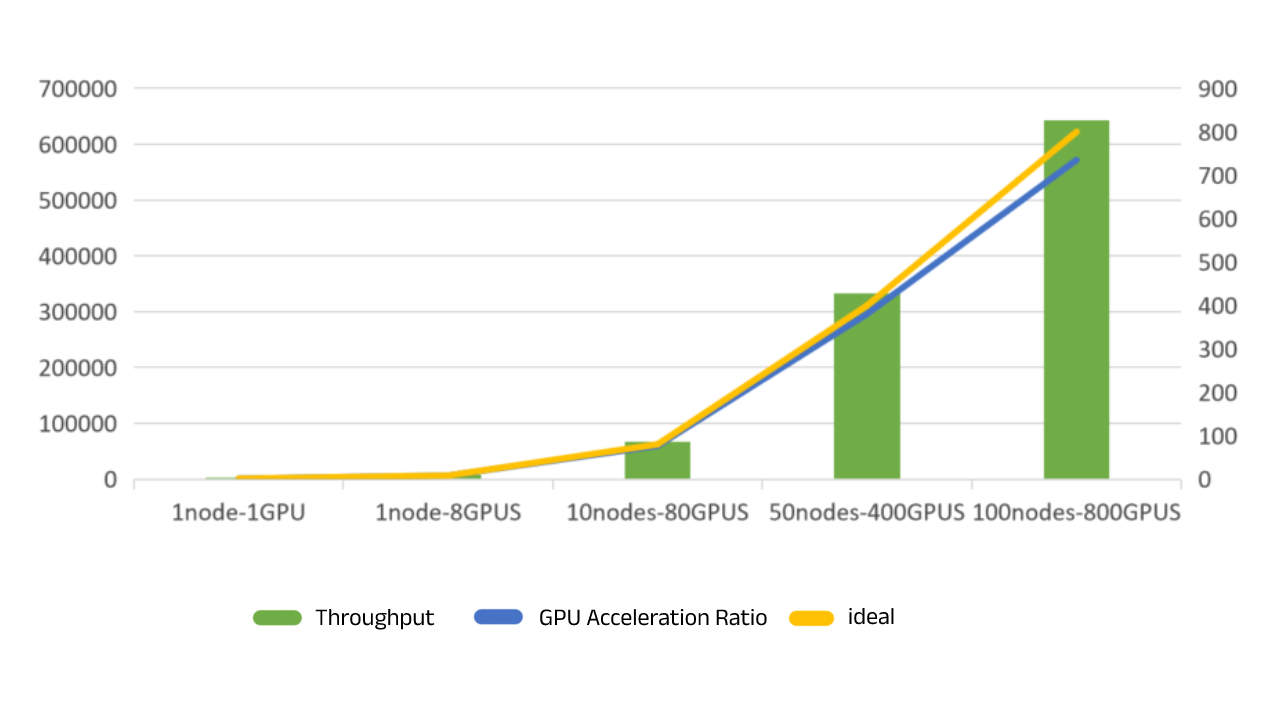




 Contact Us
Contact Us
