AI+Science Leap
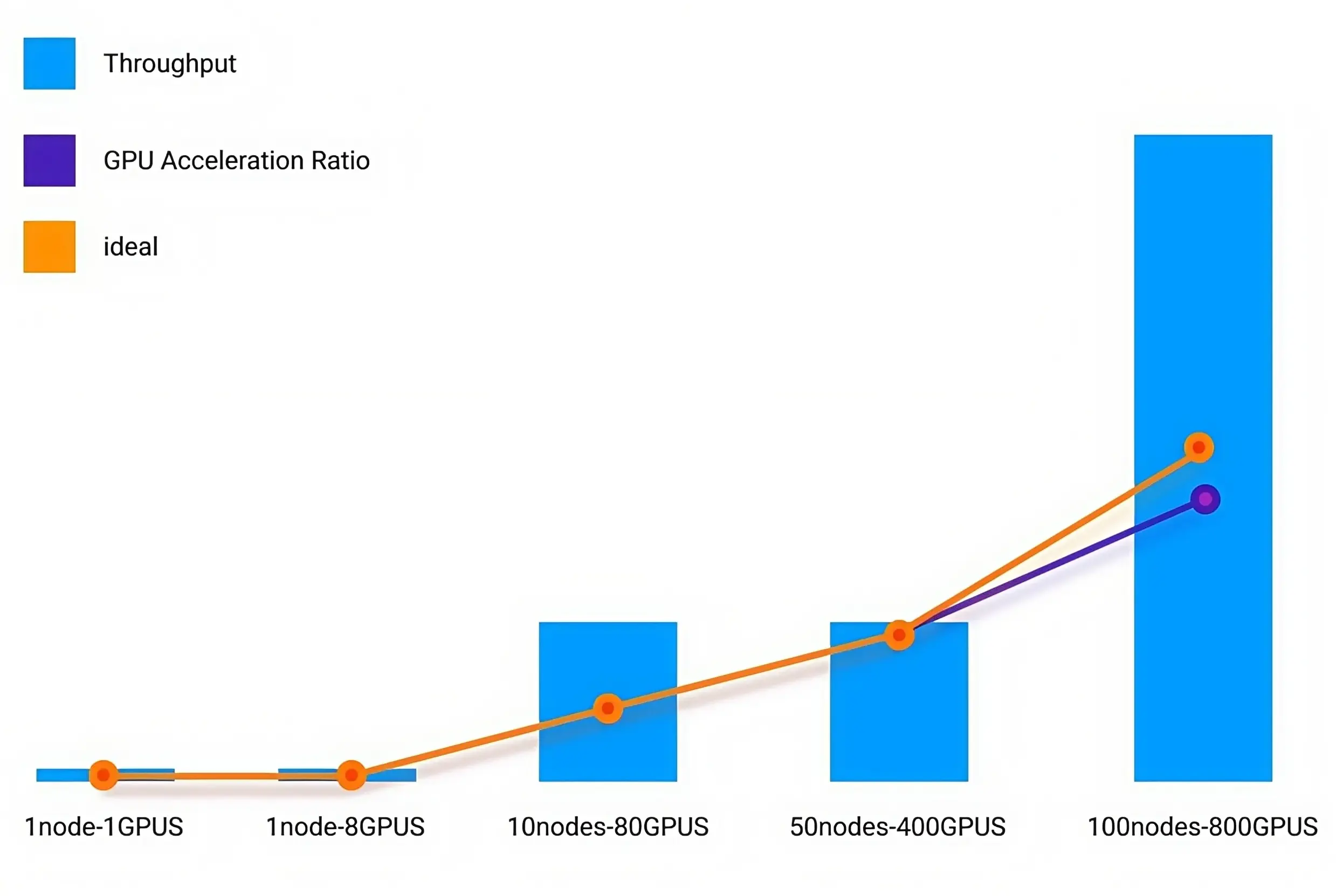
By deploying the MotusAI platform, a pioneering research university achieved over 90% GPU utilization through intelligent scheduling and GPU sharing. The solution enabled parallel processing of 30+ high-priority tasks, slashed distributed training preparation from days to hours with adaptive parameter tuning, and ensured 90% valid training time via breakpoint continuation—accelerating critical research by 5x.
Bank AI Transformation
With unified resource scheduling and automated fault recovery, MotusAI transformed the bank’s AI infrastructure, cutting model training cycles from one week to just one day. Accelerated image distribution and optimized networking amplified GPU efficiency by 7x, enabling seamless and rapid AI deployment across diverse business scenarios.
AI Manufacturing Leap
The MotusAI platform revolutionized AI-driven manufacturing with intelligent resource scheduling, reducing data transfer latency by 30% while maximizing GPU utilization efficiency. Unified platform management accelerated distributed training setup time by 8x, enabling parallel development across 10+ scenarios and cutting model iteration cycles by 75%. This innovation-driven approach has accelerated agile 3D perception advancements, driving the next wave of intelligent manufacturing.
Intelligent Computing for Autonomous Driving
With MotusAI, intelligent resource scheduling and GPU virtualization optimized computing efficiency, pushing GPU utilization to 90%. Training efficiency improved by 35%, while hyper-scale distributed task deployment enabled minute-level execution and supported 4-5 concurrent training tasks. By reducing development cycles by 67%, the solution significantly accelerated multi-vehicle ADAS deployment.
Clinical AI Breakthrough
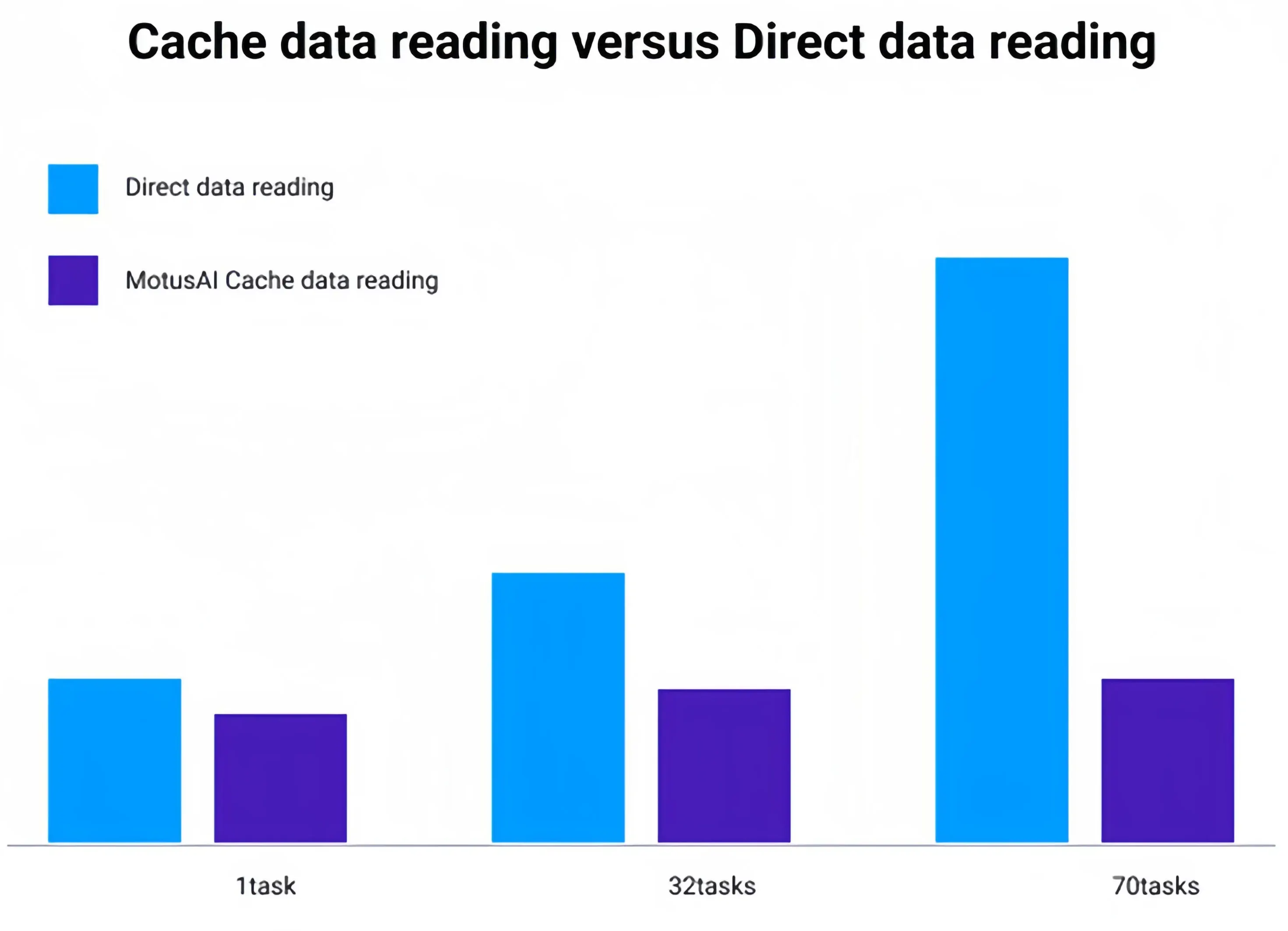
Powered by MotusAI, intelligent computing platforms optimized GPU elastic scheduling, increasing resource utilization to 80% and tripling training efficiency. The solution enabled concurrent multi-task development, breakpoint resumption, and secure data sharing, reducing project cycles by 67%. These advancements have accelerated the deployment of AI-driven applications, including surgical image recognition, enhancing precision and efficiency in clinical settings.